- Blog
Your Firm Doesn’t Need AI to Write Reports Faster

Contents
Artificial intelligence has rapidly become a huge part of the conversation across engineering, environmental consulting, and technical reporting. Yet much of the market discussion remains focused on one narrow promise: faster writing. Generate a summary, draft a section, or create a first pass of a report in seconds. And while compelling, it does not address the most meaningful constraints facing firms that produce Phase I ESAs, Property Condition Assessments, geotechnical investigations, and other technical deliverables.
For most engineering firms, the core challenge is not the speed of the actual report writing. It is the time required to locate relevant historical information, compare prior conclusions, validate consistency, and support decisions with accessible precedent. In technical consulting, the value of AI is less about generating content and far more about improving how firms use the knowledge they already possess from years of reports they’ve already written.
Key Takeaways
The bottleneck in technical reporting is access, not authorship. Most of the effort happens before the draft, when teams locate prior work, confirm how similar conditions were interpreted, and find approved language.
- Faster writing does not improve the work if the underlying information is hard to reach. In regulated, liability-sensitive work, quality depends on how well teams gather and interpret precedent.
- The most useful AI capabilities in technical reporting are search, retrieval, comparison, and traceability, all aimed at the knowledge a firm has already produced.
- When historical work becomes searchable, capacity expands without proportional hiring, QA outcomes improve across offices, and new staff ramp faster.
The Work Happens Before The Draft
Across environmental and engineering workflows, a substantial amount of effort occurs before or alongside the report draft. Project teams need to identify comparable prior engagements, review historical findings, confirm how similar conditions were previously interpreted, and locate approved language that aligns with firm standards. Each new assignment benefits from understanding what has been encountered before and how it was addressed.
For a Phase I ESA, this may involve reviewing prior reports involving similar historical land uses, petroleum operations, dry cleaners, rail corridors, or industrial adjacency. For a PCA, it often means comparing observations on roofing systems, façades, HVAC equipment, or reserve assumptions across similar asset classes. In geotechnical work, engineers may need to reference nearby subsurface conditions, groundwater observations, foundation recommendations, or slope stability considerations from earlier projects in the same region.
The challenge is that most firms store this intelligence in static documents. Reports often exist as PDFs in network folders or disconnected repositories. The information is there, but retrieving it efficiently is another matter.
Speed of Writing Was Never The Constraint
Technical firms do not succeed because they can produce paragraphs quickly. They succeed because they can apply sound judgment consistently, document conclusions clearly, and deliver reliable work under deadline. Faster writing does little to improve those outcomes if the underlying information is incomplete or difficult to access.
This is especially important in regulated or liability-sensitive work. The ASTM E1527-21 framework for Phase I ESAs emphasizes the use of historical sources, prior investigations, interviews, and reasonably ascertainable information in evaluating environmental conditions. The quality of the work is tied to how effectively teams gather and interpret relevant data, not how quickly they draft a narrative.
Similarly, in geotechnical and building assessment work, recommendations are expected to be informed by precedent, local conditions, and prior experience. A rapidly generated paragraph has limited value if it cannot be supported by evidence.
Four things AI should actually do with your reports
The most practical applications of AI in technical reporting fall into four categories: search, retrieval, comparison, and traceability.Search
Instead of manually reviewing folder names or filenames, a team should be able to ask for Phase I ESAs involving former fueling operations in a specific market, PCA reports on suburban office portfolios with roof replacement findings, or geotechnical reports near a target site with shallow groundwater conditions.Retrieval
Engineers do not need a 200-page PDF returned to them. They need the section discussing recognized environmental conditions, the table summarizing reserve costs, or the foundation recommendation tied to certain soil profiles.Comparison
If several comparable projects reached similar conclusions, that consistency is valuable. If they did not, the discrepancy may be equally important. AI can help reveal patterns that would otherwise remain buried in document archives.Traceability
In environments where defensibility matters, firms benefit from connecting recommendations to documented historical precedent rather than relying solely on memory or informal tribal knowledge.Searchable Archives Expand Capacity Without Hiring
The operational impact is direct. Faster retrieval of prior work reduces time spent searching and increases time spent applying expertise. More consistent access to precedent improves QA/QC outcomes across offices and reviewers. New hires ramp faster when they can learn from a searchable body of prior projects rather than depending entirely on senior staff availability. Senior professionals, in turn, spend less time answering repetitive questions and more time on high-value judgment.
This also affects growth. Firms often respond to rising demand by hiring, yet many delivery constraints stem from inaccessible knowledge rather than insufficient headcount. When historical work becomes usable in real time, capacity expands without requiring proportional increases in staffing.
Your Firm’s Archive, Finally Searchable
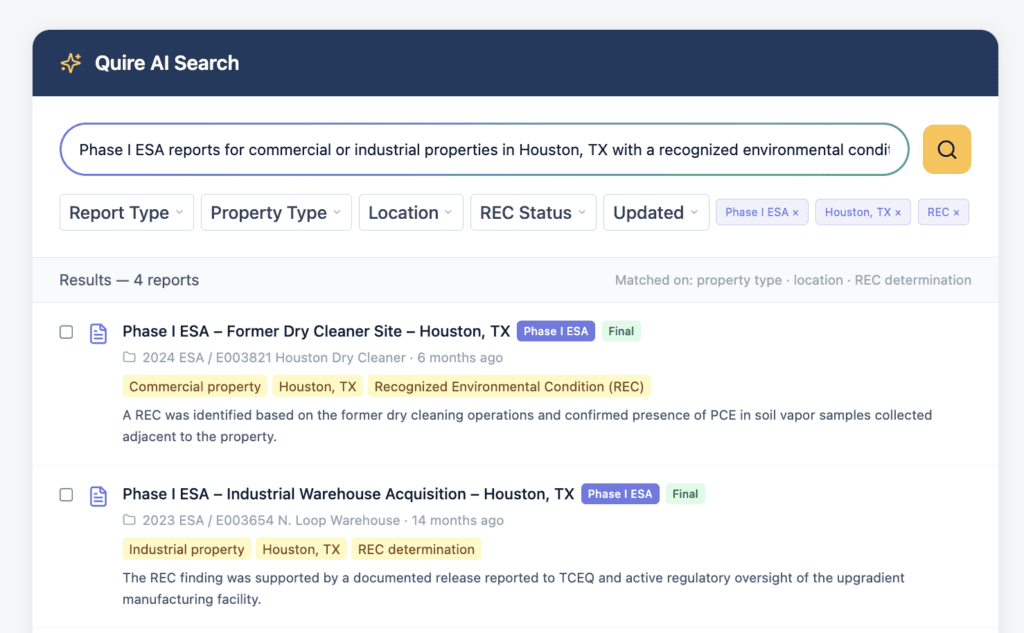
All of that knowledge is only useful if teams can reach it. That is the problem Quire is built to solve. As a technical report management platform, Quire brings AI search and chat to the deliverables your firm produces day to day. Lazarus—the historical intelligence engine from Quire—closes the gap on the rest, indexing the legacy Phase I ESAs, PCAs, and geotechnical reports that predate the platform so your full archive becomes searchable, not just recent work. Once those reports are indexed, teams can find relevant findings, compare prior conclusions, and reuse validated language with far greater speed and confidence.
For example, environmental professionals can surface prior reports involving UST/LUST proximity logic, PFAS considerations, or historical industrial corridor risk. PCA teams can find recurring building system findings across portfolios. Geotechnical teams can locate nearby projects with similar soil conditions or groundwater observations. Instead of starting with a blank page or a blind folder search, teams begin with precedent.
Put your best work back to work
A firm’s library of past reports is one of its most valuable assets, years of observations, judgments, and conclusions across thousands of projects. Left in static PDFs, that asset sits idle. Indexed and searchable, it becomes precedent the team can act on in the middle of live work.
The firms that pull ahead will not be the ones generating reports fastest. They will be the ones who can put decades of their own work to use on the project in front of them.
Frequently Asked Questions
What can AI actually do for technical reporting beyond writing?
The most practical applications are search, retrieval, comparison, and traceability across a firm’s historical work. AI can locate comparable past projects, pull the specific section or table that matters, reveal whether prior conclusions were consistent, and connect recommendations to documented precedent. Faster drafting is the least valuable of these.
What is the difference between Quire and Lazarus?
Quire is the Technical Report Management™ (TRM™) platform, with AI search and chat built in for the work a firm produces on it. Lazarus is an optional add-on that indexes legacy reports created before the firm adopted Quire, bringing those older Phase I ESAs, PCAs, and geotechnical reports into the same searchable layer as current work.
Do firms need to reformat old reports to make them searchable?
No. The point of indexing is to work with reports as they already exist, including the PDFs sitting in network folders. Teams query their history directly rather than restructuring it first, which is what makes the archive usable during active project work instead of after a manual cleanup effort.
How does searchable precedent help newer engineers?
Newer engineers can learn from a searchable body of prior projects rather than depending entirely on senior staff availability. They start a new assignment with relevant precedent instead of a blank page, which speeds ramp-up and frees senior professionals from answering the same questions repeatedly.
Put your best work back to work
Quire manages the reports your firm produces today. Lazarus makes the decades you’ve already written searchable alongside them, so every project starts with precedent instead of a blank page.


